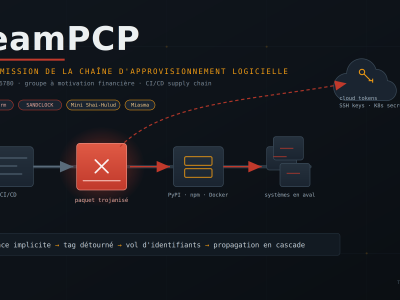
La Cyber Threat Intelligence (CTI) repose sur la collecte, l’analyse et l’interprétation de grandes quantités de données pour anticiper et prévenir les menaces cybernétiques. Dans ce contexte, l’usage de techniques statistiques permet de structurer ces informations, d’identifier des tendances et de renforcer la prise de décision en cybersécurité.
Les analystes CTI utilisent des méthodes statistiques pour filtrer les signaux pertinents, détecter des corrélations et établir des modèles prédictifs de cybermenaces. Cet article explore cinq techniques essentielles dans l’analyse des menaces : la préparation des données, la classification, la validation, la corrélation et le scoring.
1. Préparation des Données : Normalisation et Agrégation
Avant toute analyse, la préparation des données est une étape essentielle. Elle permet d’uniformiser les informations issues de multiples sources (logs de sécurité, flux réseau, bases de données d’IOC, renseignements OSINT). Elle comprend :
- La collecte des données : récupération de données provenant de SIEM, de flux Threat Intelligence, d’indicateurs de compromission (IOC) ou encore de scanners de vulnérabilités.
- La normalisation : transformation des données hétérogènes en un format exploitable.
- L’agrégation : regroupement et fusion des données selon des critères spécifiques pour obtenir une vision cohérente des menaces.
Exemple : un analyste CTI agrégera des logs provenant de plusieurs firewalls pour détecter des connexions suspectes répétitives vers des infrastructures sensibles.
2. Classification des Données : Organisation et Catégorisation
Une fois les données préparées, il est crucial de les classer pour en faciliter l’analyse et l’exploitation. La classification des données en CTI permet :
- De hiérarchiser les alertes de cybersécurité (activité suspecte, malware, exfiltration de données).
- De segreguer les IOC selon leur niveau de confiance et leur criticité.
- De mieux protéger les données en appliquant des politiques de sécurité adaptées selon leur classification.
Exemple : classer des échantillons de malwares par famille (ransomware, cheval de Troie, spyware) pour adapter la réponse aux incidents.
3. Validation des Données : Fiabilité et Exactitude
L’intégrité des informations est primordiale en CTI. Une mauvaise donnée peut entraîner une fausse alerte ou une mauvaise prise de décision. Les processus de validation des données consistent à :
- Vérifier l’origine des sources et leur fiabilité.
- Éliminer les doublons et faux positifs.
- Mettre à jour régulièrement les bases de données des menaces.
Exemple : un indicateur de compromission (IOC) peut être un faux positif si une adresse IP suspecte est en réalité un serveur VPN utilisé légitimement par un employé en télétravail.
4. Corrélation des Données : Détection de Modèles et de Relations
La corrélation des données est une technique clé pour identifier des schémas d’attaque et des tendances. Elle repose sur l’analyse de la relation entre différents événements de sécurité. Elle permet :
- De relier plusieurs événements suspects (connexion inhabituelle et exfiltration de fichiers).
- D’identifier des attaques coordonnées sur différents points d’entrée.
- De croiser les données internes avec des renseignements externes pour détecter des tactiques, techniques et procédures (TTPs) utilisées par des attaquants.
Exemple : si plusieurs entreprises signalent un phishing utilisant un domaine spécifique, la corrélation des logs permettra de confirmer une campagne de compromission ciblée.
5. Scoring des Données : Priorisation des Menaces
Dans un environnement où des milliers d’alertes sont générées chaque jour, il est indispensable de prioriser les plus critiques. Le scoring des données permet d’attribuer un niveau de criticité à un événement ou à un indicateur. Ce scoring peut être basé sur :
- Le nombre de fois qu’un IOC a été signalé.
- Son contexte d’utilisation (un malware détecté sur un serveur stratégique sera plus prioritaire qu’un poste utilisateur isolé).
- Des modèles prédictifs basés sur l’intelligence artificielle.
Exemple : un système SIEM peut attribuer un score de 0 à 100 aux alertes, en fonction du degré de menace et de l’impact potentiel.
Si je devais conclure
L’exploitation des techniques statistiques en Cyber Threat Intelligence permet d’améliorer la détection, la prévention et la réponse aux incidents.
La préparation, classification, validation, corrélation et scoring des données sont des fondamentaux pour structurer une veille de cybersécurité efficace.
Les entreprises doivent adopter ces méthodologies pour anticiper les cyberattaques et renforcer leur posture de sécurité.
L’évolution constante des cybermenaces impose une approche toujours plus fine et automatisée de l’analyse des données. L’intelligence artificielle et l’apprentissage automatique joueront un rôle clé dans l’amélioration des modèles d’analyse et de priorisation des menaces.
Enjoy
Sources
- CISA – Catalogue des vulnérabilités exploitées https://www.cisa.gov/news-events/alerts/2025/03/04/cisa-adds-four-known-exploited-vulnerabilities-catalog
- Analyse technique de la faille RCE dans Windows KDC Proxy https://cybersecuritynews.com/windows-kdc-proxy-rce-vulnerability/
- Étude sur Lotus Blossom et l’évolution du malware Sagerunex https://blog.talosintelligence.com/lotus-blossom-espionage-group/
- Vulnérabilités VMware exploitées : analyse et correctifs https://thehackernews.com/2025/03/vmware-security-flaws-exploited-in.html
- Ozkaya, Dr. Erdal. Practical Cyber Threat Intelligence